Introduction to Speech Recognition
Overview

Decoding
|
|
Speech Capture
- Wave
- Mono
- VAD (noise)
Pre-processing
- Short-time analysis: process the data window by window, as human voices have a duration of consistency within the range of 20ms to 50ms, generally we take 25ms. And make the step size of 10ms.
- FFT: converting raw wave data to frequency data.
- Cut: keep only a range of frequency data, that most human voices cover.
- Other… (DCT)
- Feature Extraction
- MFCC (mel-frequency cepstral coefficient), 39 dimentions
- PLP (perceptual linear prediction), 42 dimentions
Production-based Analysis
- Spectral Envelope
- Cepstral Analysis
- Linear Predictive Analysis
Perception-based Analysis
- Mel-Frequency Cepstrum Coefficients
- Perceptual Linear Prediction
Acoustic Model
- Acoustic model is a classification model, who’s input is the fetures, MFCC/PLP…, while output is the
phonemes, about 70 most frequently used. - Unsupervised learning
- GMM + HMM / HMM + LSTM
- Baum-Welch(EM) / MLE
GMM + HMM
HMM: modeling the states of phonemes.
GMM: modeling the output probabilities.
tri-phoneme model
Each phoneme in different context, may pronounce differently.
So setup a
Lexicon (Pronunciation Model)
words -> pronunciation in terms of phones
Language Model
For modeling the structure of sentences.
Making the sequence of words more like a human speech.
- N-gram
- WFST(Weighted Finite State Transducer)
Decoder
Viterbi algorithm: dynamic programming for combining all these to get word sequence from speech
Training
- Labels marked (hand-crafted)
- Acoustic model (EM)
Gaussians for computing P(X|Q) - Laxicon (hand-crafted)
HMM: what phones can follow each other - Language model (n-gram, RNN)
Models
GMM
HMM
$$ \lambda = (\pi, A, B) $$
- Pi: initial state probabilities matrix
- A: hidden states transition probabilities matrix
- B: output probabilities matrix (Confusion Matrix)
- S: Hidden States
- O: Observations
Problem & Solution
- Evaluation: given the observations and lamdas, find the pobability of the observation sequence -
Forword algrithm - Decoding: given the observations and lamda, find out hidden stats -
Viterbi algorithm - Learning: given the observations and learn the lamda -
Baum-Welch(forward-backward algorithm)
Viterbi
Forced alignment.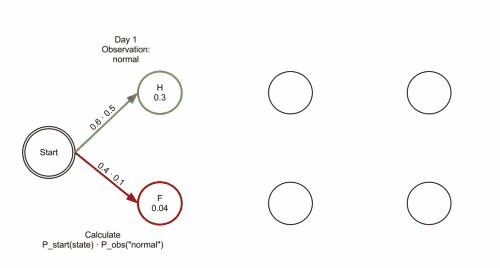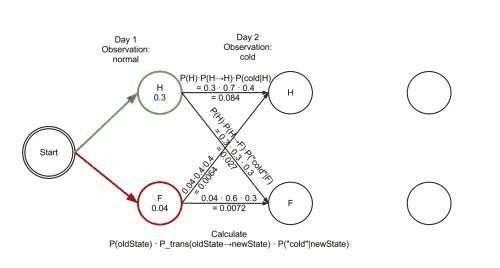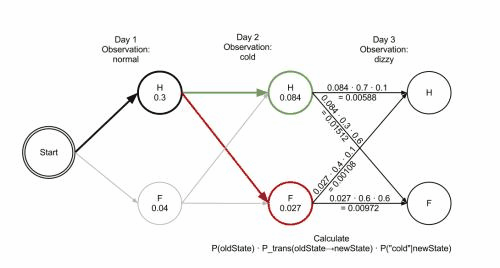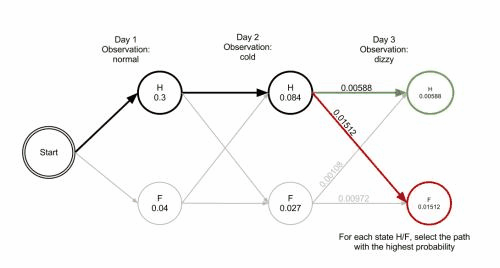
Summerize
Fumular
- X: acoustic feature vectors (observations)
- W: a word sequence
- Q: model parameters
Find the most probable word sequence Wˆ = w1,w2, . . . ,wM
given the acoustic observations X = x1, x2, . . . , xn:
$$ W^* = argmax_{w}P(W|X) $$
Applying Bayes’ Theorem:
$$ W^* = argmax_{w}\frac{P(X|W)P(W)}{P(X)} $$
P(X) is irrelevant:
$$ W^* = argmax_{w}P(X|W)P(W) $$
Words are composed of state sequences so we may express
this criterion by summing over all state sequences
Q = q1, q2, . . . , qn:
$$ W^* = argmax_{w}P(W)\sum_Q{P(Q|W)P(X|Q)} $$
Other Approaches
- HMM + GMM -> HMM + DNN + GMM(frame alignment only)
- HMM + DNN -> RNN
- end 2 end: RNN + CTC (Connectionist Temporal Classification)